Another what? Claiming to be better than gpt4? If so, I think this might be one of the most reasonable times it's been claimed, with, albeit anecdotal, evidence from real use cases instead of just gaming a benchmark
I thought they claim the dedupped dataset is the 20.5T number, where did you see 5T? either way that would still be awesome, especially when you consider the theory that quality is most limited by datasets and llama2 was trained on 2T.. this could be huge
Very interesting they wouldn't let him film the camera bump.. it must have some kind of branding on it like Hasselblad? Or maybe they've secretly found a way to have no bump! One can dream..
Yeah definitely need to still understand the open source limits, they're getting pretty dam good at generating code but their comprehension isn't quite there, I think the ideal is eventually having 2 models, one that determines the problem and what the solution would be, and another that generates the code, so that things like "fix this bug" or more vague questions like "how do I start writing this app" would be more successful
I've had decent results with continue, it's similar to copilot and actually works decently with local models lately:
It depends on the learning rate, typically it's ideal and higher quality to learn really slowly over a lot of epochs but it's cheaper and obviously faster to learn fast over fewer epochs
Also the dataset size is important to consider
Didn't do well at rag, but maybe that's because RAG is mostly handled by the wrapper rather than relying on the output of the model, think it'll matter more for langchain/guidance and the example they gave
Ah good point, definitely looking forward to it being implemented then
I feel like for non coding tasks you're sadly better off using a 13B model, codellama lost a lot of knowledge/chattiness from its coding fine tuning
THAT SAID it actually kind of depends on what you're trying to do, if you're aiming for RP don't bother, if you're thinking about summarization or logic tasks or RAG, codellama may do totally fine, so more info may help
If you have 24gb of VRAM (my assumption if you can load 34B) you could also play around with 70B at 2.4bpw using exllamav2 (if that made no sense lemme know if it interests you and I'll elaborate) but it'll probably be slower
I LOVE orca tunes, they almost always end up feeling like smarter versions of the base, so i'm looking forward to trying this one out when the GPTQ is finished
GPTQ/AWQ links:
https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GPTQ
https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ
Does sliding attention speed up inference? I thought it was more about extending the capabilities of the context above what it was trained on. I suppose I could see it being used to drop context which would save on memory/inference, but didn't think that was the point of it, just a happy side effect, i could be wrong though
Will have to try to use this with some RAG/langchain/guidance to see if it's any better at it..
14
A note on the importance of prompt and template formatting - as seen from starcoder
(self.localllama)
So I was playing around with some coding models and getting disappointed in the responses. I started using starcoderplus-guanaco-gpt4, and after some tinkering I just wanted to share the importance of formatting your prompt correctly
I asked to provide a way to rate limit a function in python based on the input to the function so that it doesn't repeat identical output too often
I used the following prompt:
Create a python function that takes a string as input and prints that string. The function should be rate limited so that any specific string is not printed more than once every two minutes. This means it must keep track of the last time that it printed a specific string.
However, I used it in the chat-completion UI of text-generation-webui, and this was the useless reply I got:
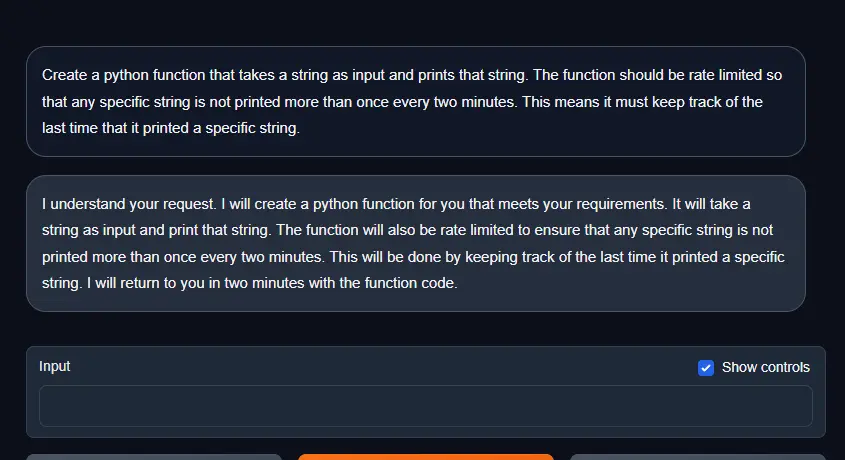
Obviously completely useless to me
But then I realized that this model expects to follow instructions, not a chat, so I went over to the instruction template so now this was my "prompt":
### Instruction: Create a python function that takes a string as input and prints that string. The function should be rate limited so that any specific string is not printed more than once every two minutes. This means it must keep track of the last time that it printed a specific string.
### Response:
And lo and behold, a very competent useful reply!
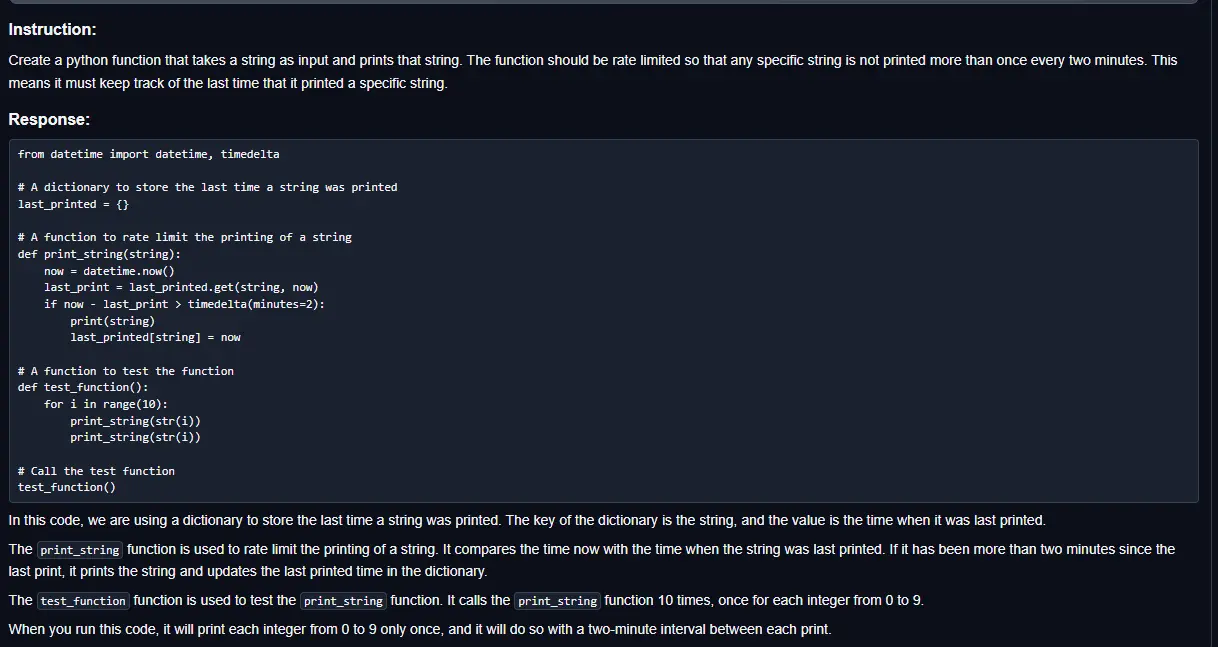
As you can see, even if you follow the proper concept for instruct (providing it as instructions 'Create a python function that..' rather than 'I need a function that..'), you still need to be sure to follow the proper template structure.
And most interestingly of all, giving the same prompt to chatgpt gets what I consider to be a worse answer:
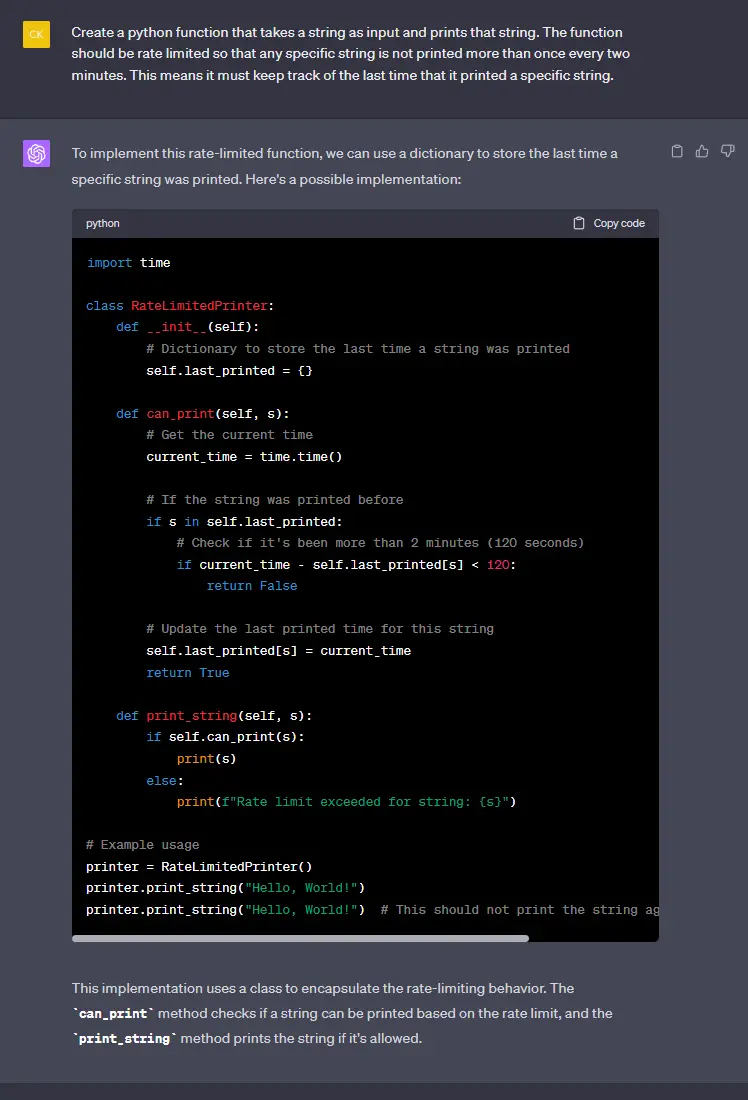
It's very similar but to my eye distinctly overengineered, I find the solution from starcoder much more closely answers my question with only a couple lines of code to change my existing function. YMMV, but the TLDR is that you should make sure to follow the proper prompt and template formats to get the best replies from your model
I think the implication is more stating that this dataset is even more useful if you don't jam the whole thing into your training but instead further filter it to a reasonable number of tokens, around 5T, and train on that subset instead
I could be incorrect, cause they do explicitly say deduplicating, but it's phrased oddly either way