Hello everyone, we're long overdue for an update on how things have been going!
Finances
Since we started accepting donations back in July we've received a total of $1350, as well as $1707 in older donations from smorks. We haven't had any expenses other than OVH (approx $155/mo) since then, leaving us $2152 in the bank.
We still owe TruckBC $1980 for the period he was covering hosting, and I've contributed $525 as well (mostly non-profit registration related stuff, plus domain renewals). We haven't yet discussed reimbursing either of us, we're both happy to build up a contingency fund for a while.
New Server
A few weeks ago, we experienced a ~26-hour outage due to a failed power supply and extremely slow response times from OVH support. This was followed by an unexplained outage the next morning at the same time. To ensure Lemmy’s growth remains sustainable for the long term and to support other federated applications, I’ve donated a new physical server. This will give us a significant boost in resources while keeping the monthly cost increase minimal.
Our system specs today:
- Undoubtedly the cheapest hardware OVH could buy
- Intel Xeon E-2386G (6 cores @ 3.5ghz)
- 32gb of ram
- 2x 512gb Samsung nvme in raid 1
- 1gb network
- $155/month
The new system:
- Dell R7525
- AMD EPYC 7763 (64 cores @ 2.45ghz)
- 1tb of ram
- 3x 120gb sata ssd (hw raid 1 with a hot spare, for proxmox)
- 4x 6.4tb nvme (zfs mirrored + striped, for data)
- 1gb network with a 50mbit commit (See 95th percentile billing)
- Redundant power supplies
- Next day hardware support until Aug 2027
- $166/month + tax
This means instead of renting an entire server and having them be responsible for the hardware, we'll be renting co-location space at a Vancouver datacenter PDF via a 3rd party service provider I know.
These servers are extremely reliable but if there is a failure, either Otter or myself will be able to get access reasonably quickly. We also have full OOB access via idrac, so it's pretty unlikely we'll ever need to go on site.
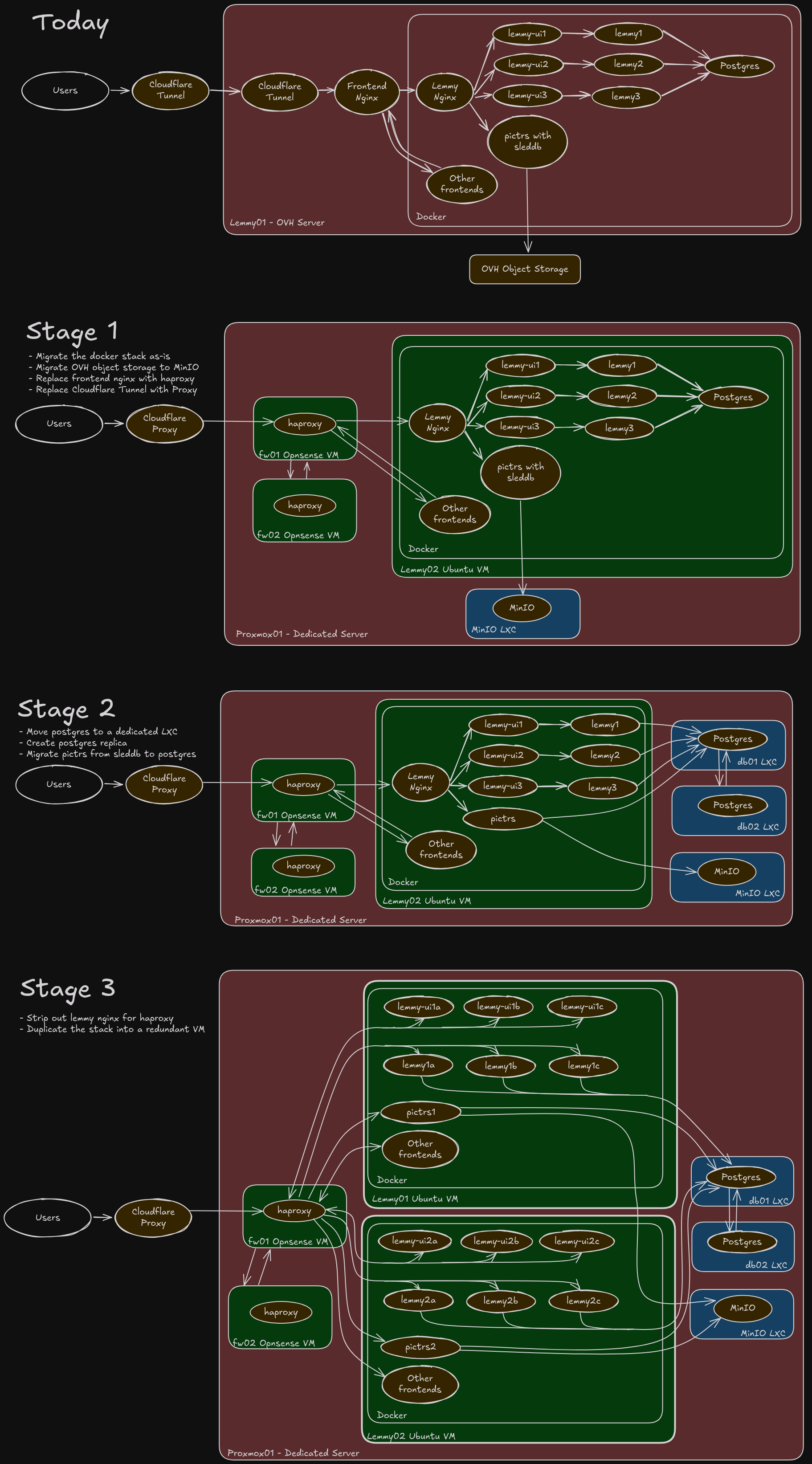
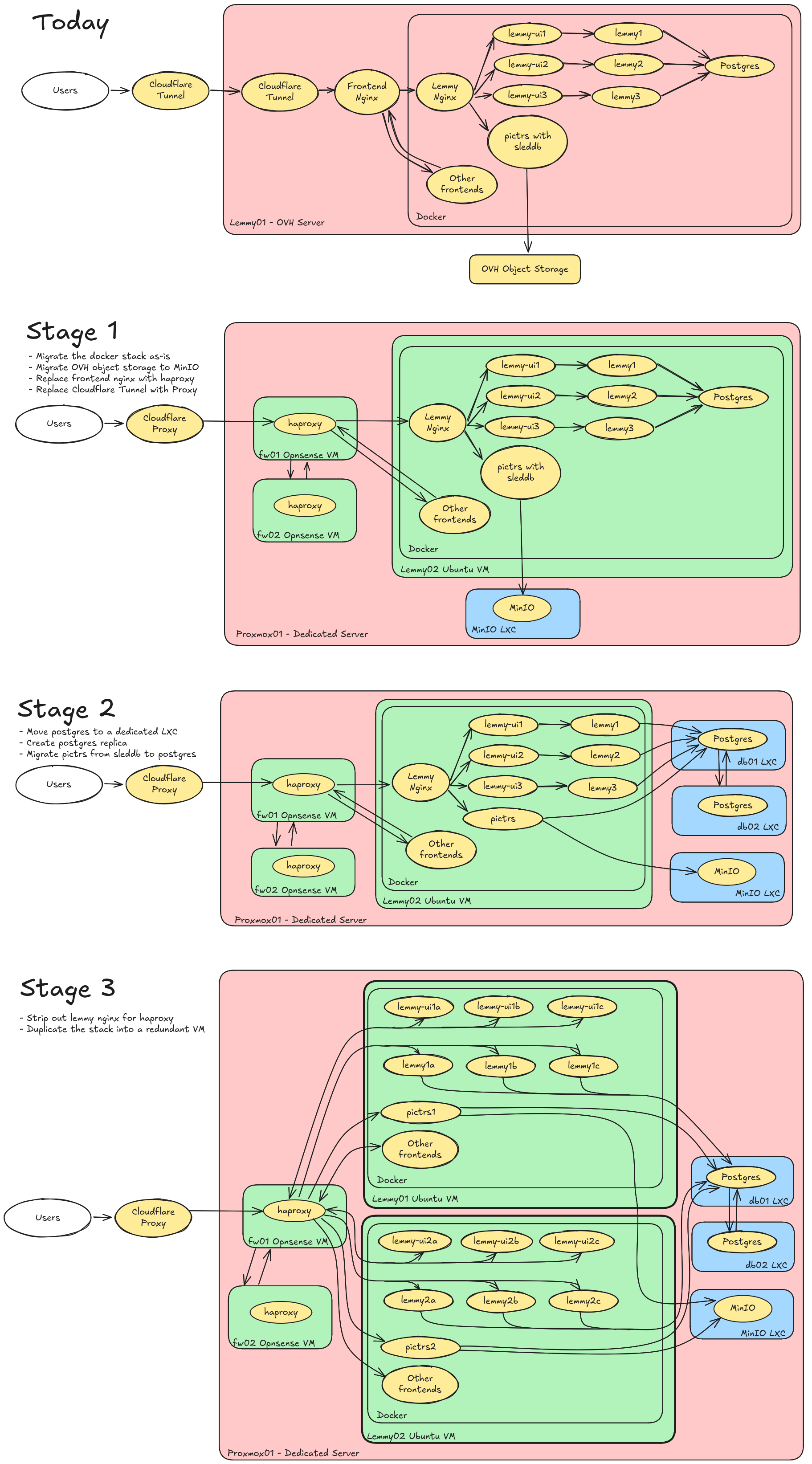
Server Migration
Phase 1 is currently planned for Jan 29th or 30th and will completely move us out of OVH and onto our own hardware. I'm expecting probably a 2-3 hour outage, followed by an 6-8 hour window where some images may be missing as the object store resyncs. I'll make another follow up post in a week with specifics.
Phases 2+ I'm not 100% decided on yet and have not planned a timeline around. It would get us into a fully redundant (excluding hardware) setup that's easier to scale and manage down the road, but it does add a little bit of complexity.
{kind=link}
{kind=link}
Let me know if you have any questions or comments, or feedback on the architecture!