Yesterday I got bored and decided to try out my old GPUs with Vulkan. I had an HD 5830, GTX 460 and GTX 770 4Gb laying around so I figured "Why not".
Long story short - Vulkan didn't recognize them, hell, Linux didn't even recognize them. They didn't show up in nvtop, nvidia-smi or anything. I didn't think to check dmesg.
Honestly, I thought the 770 would work; it hasn't been in legacy status that long. It might work with an older Nvidia driver version (I'm on 550 now) but I'm not messing with that stuff just because I'm bored.
So for now the oldest GPUs I can get running are a Ryzen 5700G APU and 1080ti. Both Vega and Pascal came out in early 2017 according to Wikipedia. Those people disappointed that their RX 500 and RX 5000 don't work in Ollama should give Llama.cpp Vulkan a shot. Kobold has a Vulkan option too.
The 5700G works fine alongside Nvidia GPUs in Vulkan. The performance is what you'd expect from an APU, but at least it works. Now I'm tempted to buy a 7600 XT just to see how it does.
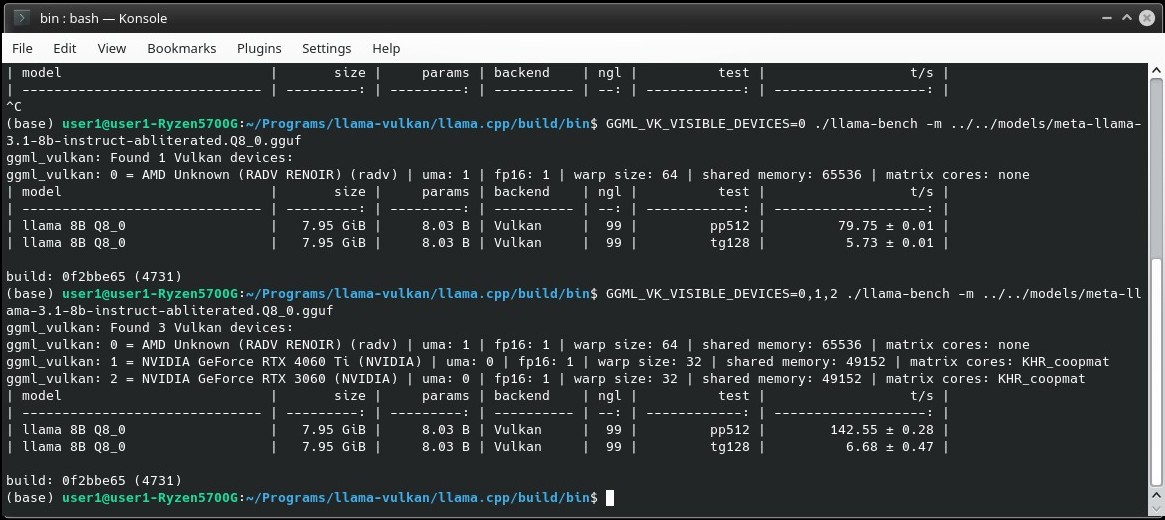
Has anyone else out there tried Vulkan?
Is BLAS faster with CPU only than Vulkan with CPU+iGPU? After failing to make work the SYCL backend in llama.cpp apparently because of a Debian driver issue I ended up using the Vulkan backend but after many tests offloadding to the iGPU doesn't seem to make much difference.
Uh, that's a complicated question. I don't know whether BLAS or Vulkan or SyCL are faster on an iGPU. I think I read many different takes on that. And I suppose it probably changed since I last tested it. People are optimizing the code all the time and it probably also depends on the processor generation and things like that. All I can say setting up SyCL is a hassle and requires like 10GB of development libraries. And I didn't see any noticeable improvement in speed. Either I did something wrong or it's not worth it on my computer. And Vulkan made everything slower on my 8th generation laptop's iGPU. But I'm not sure if that applies generally. But I'm currently sticking to the default backend, I believe that's BLAS. But again on KoboldCPP they replaced OpenBLAS with NoBLAS(?) recently and I haven't kept up to date and it's just too many options... 😅 I don't have any good advice. Maybe try all the options and see which is the fastest... Seems to me using the iGPU likely makes it slower, not faster.