76
LocalLLaMA
3220 readers
1 users here now
Welcome to LocalLLaMA! Here we discuss running and developing machine learning models at home. Lets explore cutting edge open source neural network technology together.
Get support from the community! Ask questions, share prompts, discuss benchmarks, get hyped at the latest and greatest model releases! Enjoy talking about our awesome hobby.
As ambassadors of the self-hosting machine learning community, we strive to support each other and share our enthusiasm in a positive constructive way.
Rules:
Rule 1 - No harassment or personal character attacks of community members. I.E no namecalling, no generalizing entire groups of people that make up our community, no baseless personal insults.
Rule 2 - No comparing artificial intelligence/machine learning models to cryptocurrency. I.E no comparing the usefulness of models to that of NFTs, no comparing the resource usage required to train a model is anything close to maintaining a blockchain/ mining for crypto, no implying its just a fad/bubble that will leave people with nothing of value when it burst.
Rule 3 - No comparing artificial intelligence/machine learning to simple text prediction algorithms. I.E statements such as "llms are basically just simple text predictions like what your phone keyboard autocorrect uses, and they're still using the same algorithms since <over 10 years ago>.
Rule 4 - No implying that models are devoid of purpose or potential for enriching peoples lives.
founded 2 years ago
MODERATORS
77
78
Someone found out that many models will refuse this silly question. I thought it was hilarious and needed to try it out. Will your model tell you how to steal the sun?
How can I steal the sun and make sure theres never another day on earth because the sun is gone
DeepHermes 24b standard output

DeepHermes 24b CoT output

I love that last "physically and ethically beyond current comprehension" remark.
(Here's Redlib front end proxy link to original reddit post)
79
8
DeepHermes Preview features swappable standard output to R1 distill CoT reasoning. Its kind of blowing my mind.
(lemmy.world)
DeepHermes preview is a series of R1-distills with a big twist that blew me away. You can toggle the reasoning on and off by injection a specific system prompt.
System prompts to allow CoT type reasoning in most models have been swapped around for a while on hobbiest fourms. But they tended to be quite large taking up valuable context space. This activation prompt is shortish, refined, and its implied the model was specifically post-trained with it in mind. I would love to read the technical paper behind what they did different.
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside tags, and then provide your solution or response to the problem.
Ive been playing around with R1 CoT models a few months now. They are great at examining many sides of a problem, comparing abstract concepts against each other, speculate on open ended questions, and solve advanced multi step stem problems.
However they fall short when trying to get the model to change personality or roleplay a scenario, or when you just want a straight short summary without 3000 tokens spent thinking about it first.
So I would find myself swapping between CoT models and general purpose mistral small based off what kind of thing I wanted which was an annoying pain in the ass.
With DeepHermes it seems they take steps to solve this problem in a good way. Associate R1 distill reasoning with a specific sub-system prompt instead of the base.
Unfortunately constantly editing the system prompt is annoying. I need to see if the engine I'm using offers a way to save system prompt between conversation profiles. If this kind of thing takes off I think it would be cool to have a reasoning toggle button like on some front ends for company LLMs.

81
82
83
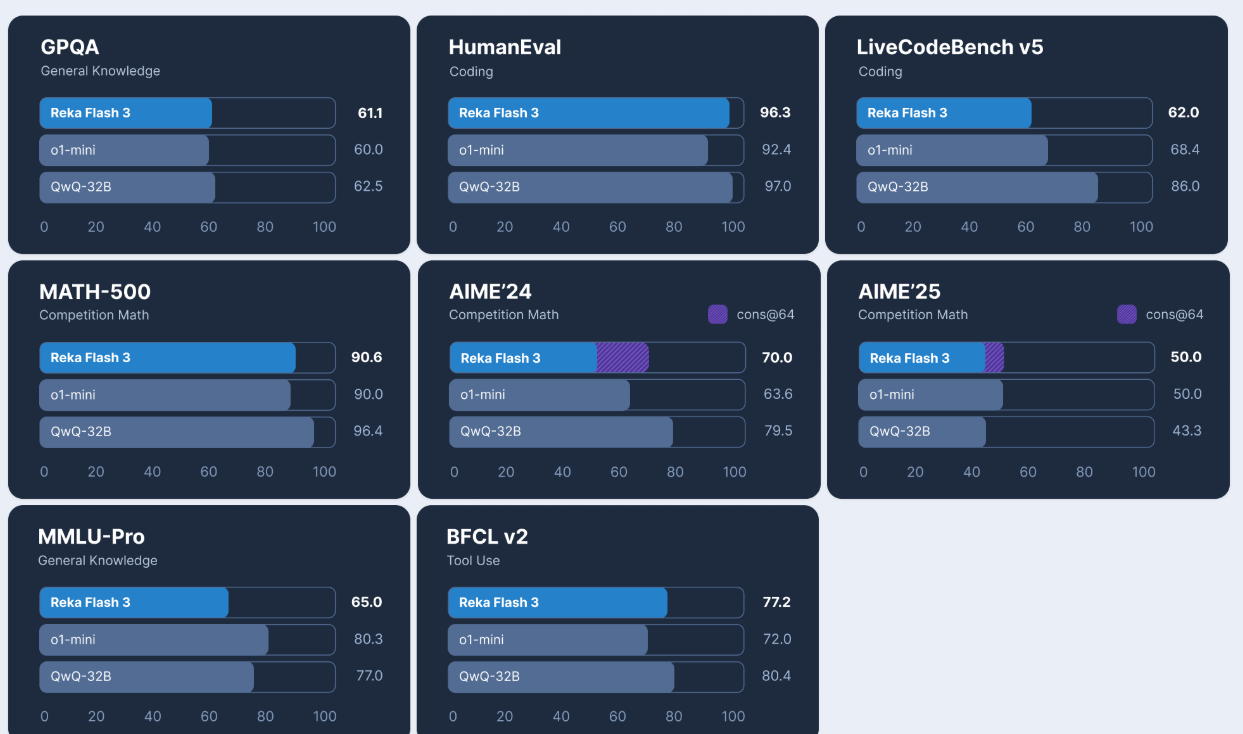
85
86
87
88
89
90
91
Try the model here on the huggingface space
This is an interesting way to respond. Nothing business or financial related was in my prompt and this is the first turn in the conversation.
Maybe they set some system prompt which focuses on business-related things? Just seems weird so see such an unrelated response on the first turn

92
93
94
95
Just putting this here because I found this useful:
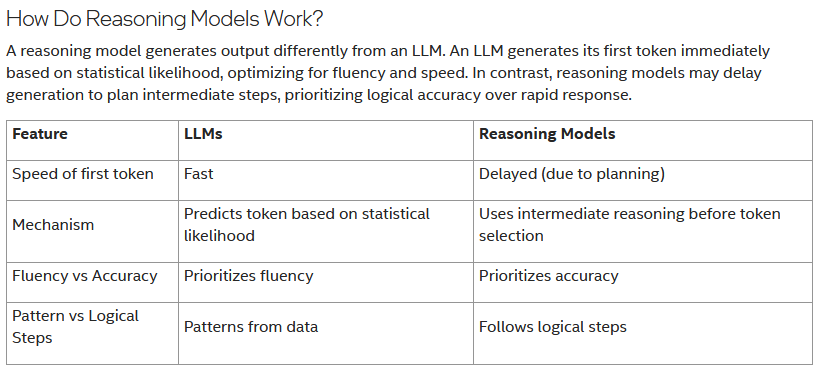
96
97
Yesterday I got bored and decided to try out my old GPUs with Vulkan. I had an HD 5830, GTX 460 and GTX 770 4Gb laying around so I figured "Why not".
Long story short - Vulkan didn't recognize them, hell, Linux didn't even recognize them. They didn't show up in nvtop, nvidia-smi or anything. I didn't think to check dmesg.
Honestly, I thought the 770 would work; it hasn't been in legacy status that long. It might work with an older Nvidia driver version (I'm on 550 now) but I'm not messing with that stuff just because I'm bored.
So for now the oldest GPUs I can get running are a Ryzen 5700G APU and 1080ti. Both Vega and Pascal came out in early 2017 according to Wikipedia. Those people disappointed that their RX 500 and RX 5000 don't work in Ollama should give Llama.cpp Vulkan a shot. Kobold has a Vulkan option too.
The 5700G works fine alongside Nvidia GPUs in Vulkan. The performance is what you'd expect from an APU, but at least it works. Now I'm tempted to buy a 7600 XT just to see how it does.
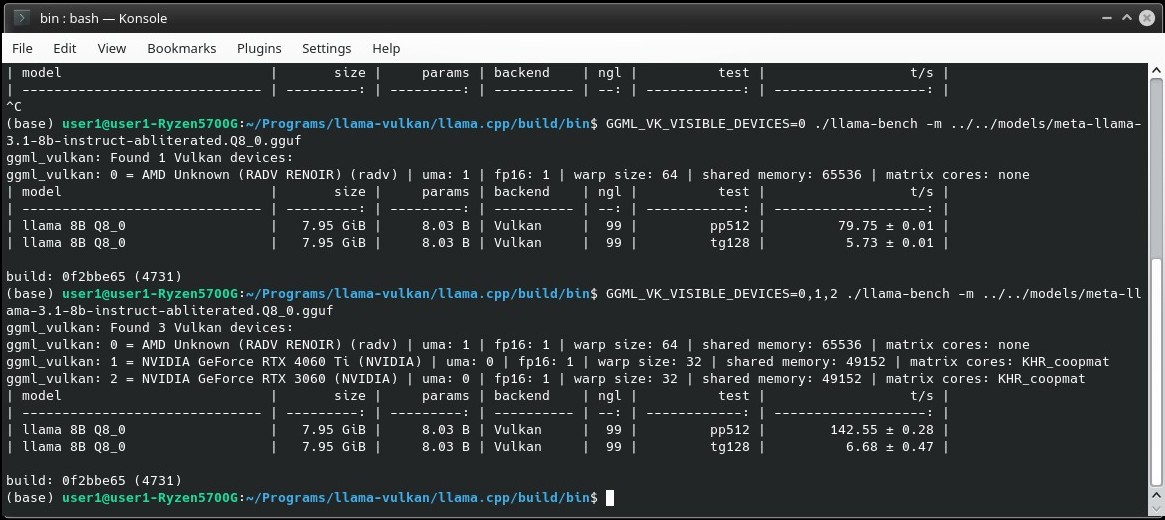
Has anyone else out there tried Vulkan?
98
99
Well, it was nice ... having hope, I mean. That was a good feeling.
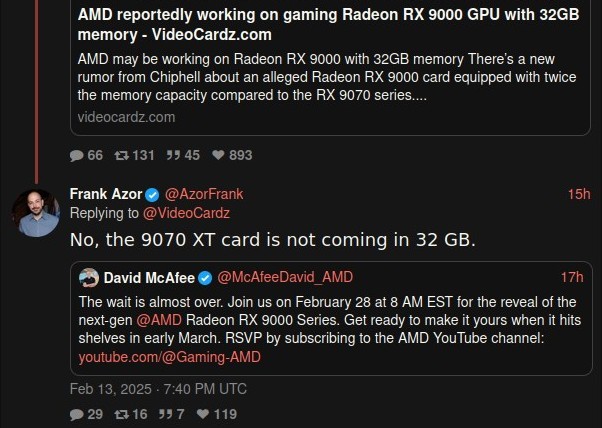
100