Hello. It is I, Tiff. I am not dead contrary to my lack of Reddthat updates 😅 !
It's been a fun few months since our last update. We've been mainlining those beta releases, found critical performance issues before they made it into the wider Lemmyverse and helped the rest of the Lemmyverse update from Postgres 15 to 16 as part of the updates for Lemmy versions 0.19.4 and 0.19.5!
Thank-you to everyone who helped out in the matrix admin rooms as well as others who have made improvements which will allow us to streamline the setup for all future upgrades.
And a huge thank you to everyone who has stuck around as a Reddthat user too! Without you all this little corner of the world wouldn't have been possible. I havn't been as active as I should be for Reddthat, moderating, diagnosing issues and helping other admins has been taking the majority of my Reddthat allocated time. Creating these "monthly" updates should... be monthly at least! so I'll attempt start posting them monthly, even if nothing is really happening!
High CPU Usages / Long Load Times
Unfortunately you may have noticed some longer page load times with Reddthat, but we are not alone! These issues are with Lemmy as a whole! Since the 0.19.x releases many people have talked about Lemmy having an increase in CPU usage, and they have the monitoring to prove it too. On average there was a 20% increase and for those who have single user instance this was a significant increase. Especially when people were using a raspberry pi or some other small form factor device to run their instance.
This increase was one of the many reasons why our server migrations were required a couple months ago. There is good news believe it or not! We found the issue with the long page load times, and helped the developers find the solution! -
This change looks like it will be merged within the next couple days. Once we've done our own testing, we will backport the commit and start creating our own Lemmy 'version'. Any backporting will be met with scrutiny and I will only cherry-pick the bare minimum to ensure we never get into a situation where we are required to use the beta releases. Stability is one of my core beliefs and ensuring we all have a great time!
Donation Drive
We need some recurring donations!
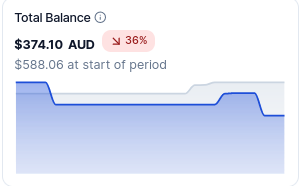
We currently have $374.10 and our operating costs have slowly been creeping up over the course of the last few months. Especially with the current currency conversions. The current deficit is $74. Even with the amazing 12 current users we will run out of money in 5 months. That's January next year! We need another 15 users to donate $5/month and we'd be breaking even. That's 1 coffee a month.
If you are financially able please see the sidebar for donation options, go to our funding post , or go directly to our Open Collective and signup for recurring donations!
Our finances are viewable to all and you can see the latest expense here: https://opencollective.com/reddthat/expenses/213722
- OVH Server (Main Server) - $119.42 AUD
- Wasabi S3 (Image Hosting) - $16.85 AUD
- Scaleway Server (LemmyWorld Proxy) - $6.62 AUD
Scaleway
Unfortunately until Lemmy optimises their activity sending we still need a proxy in EU, and I havn't found any server that is cheaper than €3.99. If you know of something with 1GB RAM with an IPv4 thats less than that let me know. The good news is that Lemmy.ml is currently testing their new sending capabilities so it's possible that we will be able to eventually remove the server in the next year or so. The biggest cost in scaleway is actually the IPv4. The server itself is less than €1.50 so if lemmy.world had IPv6 we could in theory save €1.50/m. In saying all this, that saving per month is not a lot of money!
Wasabi
Wasabi S3 is also one of those interesting items where in theory it should only be USD$7, but in reality they are charging us closer to USD$11.
They charge a premium for any storage that is deleted before 30 days, as they are meant to be an "archive" instead of a hot storage system.
This means that all images that are deleted before 30 days incur a cost. Over the last 30 days that has amounted to 305GB! So while we don't get charged for outbound traffic, we are still paying more than the USD$7 per month.
We've already tried setting the pictrs caching to auto-delete the thumbnails after 30 days rather than the default 7 days, but people still upload and delete files, and close our their accounts and delete everything. I expect this to happen and want people to be able to delete their content if they wish.
OVH Server
When I migrated the server in April we were having database issues. As such we purchased a server with more memory (ram) than the size of the database, which is the general idea when sizing a database. Memory: 32 GB. Unfortunately I was thinking on a purely technical level rather than what we could realistically afford and now we are paying the price. Literally. (I also forgot it was in USD not AUD :| )
Again, having the extra ram gives us the ability to host our other frontends, trial new features, and ensure we are going to be online incase there are other issues. Eventually we will also increase our Lemmy applications from 1 to 2 and this extra headroom will facilitate this.
Donate your CPU! (Trialing)
If you are unable to donate money that is okay too and here is another option! You can donate your CPU power instead to help us mine crypto coins, anonymously! This is a new initiative we are trialing. We have setup a P2Pool at: https://donate.reddthat.com. More information about joining the mining pool can be found there. The general idea is: download a mining program, enter in our pool details, start mining, when our pool finds a "block", we'll get paid.
I've been testing this myself as an option of the past month as a "side hustle" on some laptops. Over the past 30 days I managed to make $5. Which is not terrible if we can scale it out. If it doesn't takes off, that's fine too!
I understand some people will be hesitant for any of the many reasons that exist against crypto, but any option to help us pay our server bills and allow people to donate in an anonymous way is always a boon for me.
Conclusion
These Lemmy bugs have been causing a headache for me in diagnosing and finding solutions. With the upcoming 0.19.6 release I hope that we can put this behind us and Reddthat will be better for it.
Again, thank you all for sticking around in our times of instabilities, posting, commenting and engaging in thoughtful communications.
You are all amazing.
Cheers,
Tiff



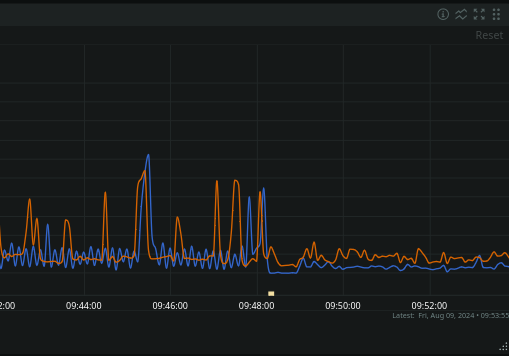

It's certainly not too big, as we can upload 25MB images without issue!
This is probably a bug with Lemmy as we have not upgraded to the latest version. 0.19.8 has a thumbnail issue that was resolved so it's possible that it's related.
I'll schedule it for Tuesday around 00:00 UTC.
Hopefully once that is done it will be all sorted!