26
Singularity | Artificial Intelligence (ai), Technology & Futurology
96 readers
1 users here now
About:
This sublemmy is a place for sharing news and discussions about artificial intelligence, core developments of humanity's technology and societal changes that come with them. Basically futurology sublemmy centered around ai but not limited to ai only.
Rules:
- Posts that don't follow the rules and don't comply with them after being pointed out that they break the rules will be deleted no matter how much engagement they got and then reposted by me in a way that follows the rules. I'm going to wait for max 2 days for the poster to comply with the rules before I decide to do this.
- No Low-quality/Wildly Speculative Posts.
- Keep posts on topic.
- Don't make posts with link/s to paywalled articles as their main focus.
- No posts linking to reddit posts.
- Memes are fine as long they are quality or/and can lead to serious on topic discussions. If we end up having too much memes we will do meme specific singularity sublemmy.
- Titles must include information on how old the source is in this format dd.mm.yyyy (ex. 24.06.2023).
- Please be respectful to each other.
- No summaries made by LLMs. I would like to keep quality of comments as high as possible.
- (Rule implemented 30.06.2023) Don't make posts with link/s to tweets as their main focus. Melon decided that the content on the platform is going to be locked behind login requirement and I'm not going to force everyone to make a twitter account just so they can see some news.
- No ai generated images/videos unless their role is to represent new advancements in generative technology which are not older that 1 month.
- If the title of the post isn't an original title of the article or paper then the first thing in the body of the post should be an original title written in this format "Original title: {title here}".
- Please be respectful to each other.

Related sublemmies:
[email protected] (Our community focuses on programming-oriented, hype-free discussion of Artificial Intelligence (AI) topics. We aim to curate content that truly contributes to the understanding and practical application of AI, making it, as the name suggests, “actually useful” for developers and enthusiasts alike.)
Note:
My posts on this sub are currently VERY reliant on getting info from r/singularity and other subreddits on reddit. I'm planning to at some point make a list of sites that write/aggregate news that this subreddit is about so we could get news faster and not rely on reddit as much. If you know any good sites please dm me.
founded 2 years ago
MODERATORS
27
28

30
31
32

32
5
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning (paper from 12.07.2023)
(cdn-uploads.huggingface.co)
33
34
35
36
37
38
39
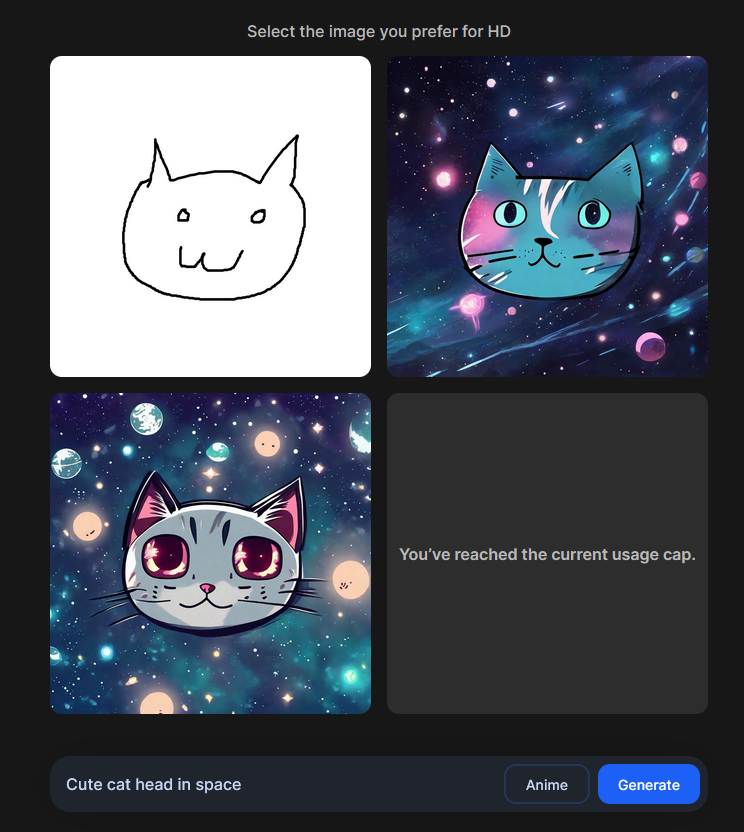
Stability AI launches a web tool that allows you to turn your doodles into pretty AI-generated images: https://clipdrop.co/stable-doodle
It's not clear what the free daily limit is, but it seems to be about 3 prompts every hour. Results are pretty neat.
40
41
42
43
44
45
46
47
49
The alignment-minetest project just put out a new blog post detailing what we've been working on for the past several months.
The post is titled "Minetester: A fully open RL environment built on Minetest" and covers:
-
The minetester framework and how it relates to existing efforts in ai for Minecraft
-
A PPO baseline and environment customization using the framework.
-
Basic interpretability work we did on the learned PPO policy.
-
General and specific takeaways from our work so far.
-
Next steps for the project.
Relevant Links:
Blog Post: https://blog.eleuther.ai/minetester-intro/
Minetest Channel: https://discord.com/channels/729741769192767510/1014999314835181650
Minetester Repo: https://github.com/EleutherAI/minetest/
Minetester Baselines: https://github.com/EleutherAI/minetest-baselines/
Interpretabilty Notebook: https://github.com/EleutherAI/minetest-interpretabilty-notebook
Special thanks to @rkla @nev and @Eduuu for their major contributions to the project. Additional thanks to @josiah_wi and @Delta for their contributions.
Martineski: I got the announcement on this dc server: https://discord.gg/AY2Hg2qj
Direct link to the announcement: https://discord.com/channels/729741769192767510/794042109048651818/1127288927888343084

50