Singularity | Artificial Intelligence (ai), Technology & Futurology
96 readers
1 users here now
About:
This sublemmy is a place for sharing news and discussions about artificial intelligence, core developments of humanity's technology and societal changes that come with them. Basically futurology sublemmy centered around ai but not limited to ai only.
Rules:
- Posts that don't follow the rules and don't comply with them after being pointed out that they break the rules will be deleted no matter how much engagement they got and then reposted by me in a way that follows the rules. I'm going to wait for max 2 days for the poster to comply with the rules before I decide to do this.
- No Low-quality/Wildly Speculative Posts.
- Keep posts on topic.
- Don't make posts with link/s to paywalled articles as their main focus.
- No posts linking to reddit posts.
- Memes are fine as long they are quality or/and can lead to serious on topic discussions. If we end up having too much memes we will do meme specific singularity sublemmy.
- Titles must include information on how old the source is in this format dd.mm.yyyy (ex. 24.06.2023).
- Please be respectful to each other.
- No summaries made by LLMs. I would like to keep quality of comments as high as possible.
- (Rule implemented 30.06.2023) Don't make posts with link/s to tweets as their main focus. Melon decided that the content on the platform is going to be locked behind login requirement and I'm not going to force everyone to make a twitter account just so they can see some news.
- No ai generated images/videos unless their role is to represent new advancements in generative technology which are not older that 1 month.
- If the title of the post isn't an original title of the article or paper then the first thing in the body of the post should be an original title written in this format "Original title: {title here}".
- Please be respectful to each other.

Related sublemmies:
[email protected] (Our community focuses on programming-oriented, hype-free discussion of Artificial Intelligence (AI) topics. We aim to curate content that truly contributes to the understanding and practical application of AI, making it, as the name suggests, “actually useful” for developers and enthusiasts alike.)
Note:
My posts on this sub are currently VERY reliant on getting info from r/singularity and other subreddits on reddit. I'm planning to at some point make a list of sites that write/aggregate news that this subreddit is about so we could get news faster and not rely on reddit as much. If you know any good sites please dm me.
founded 1 year ago
MODERATORS
1
2
3
4
5
7
8
9
10
11
12
13
14
15
16
23
A.I. Health scans are going to become the Norm (Article from 11.07.2023)
(aisupremacy.substack.com)
17
4
Large Language Models as General Pattern Machines (paper from 10.07.2023)
(general-pattern-machines.github.io)
18
19
20
21
18
Introducing Llama 2 - Meta's Next-Generation Commercially Viable Open-Source AI & LLM (paper from 18.07.2023)
(lemmy.dbzer0.com)
cross-posted from: https://lemmy.world/post/1750098
Introducing Llama 2 - Meta's Next Generation Free Open-Source Artificially Intelligent Large Language Model
It's incredible it's already here! This is great news for everyone in free open-source artificial intelligence.
Llama 2 unleashes Meta's (previously) closed model (Llama) to become free open-source AI, accelerating access and development for large language models (LLMs).
This marks a significant step in machine learning and deep learning technologies. With this move, a widely supported LLM can become a viable choice for businesses, developers, and entrepreneurs to innovate our future using a model that the community has been eagerly awaiting since its initial leak earlier this year.
Here are some highlights from the official Meta AI announcement:
Llama 2
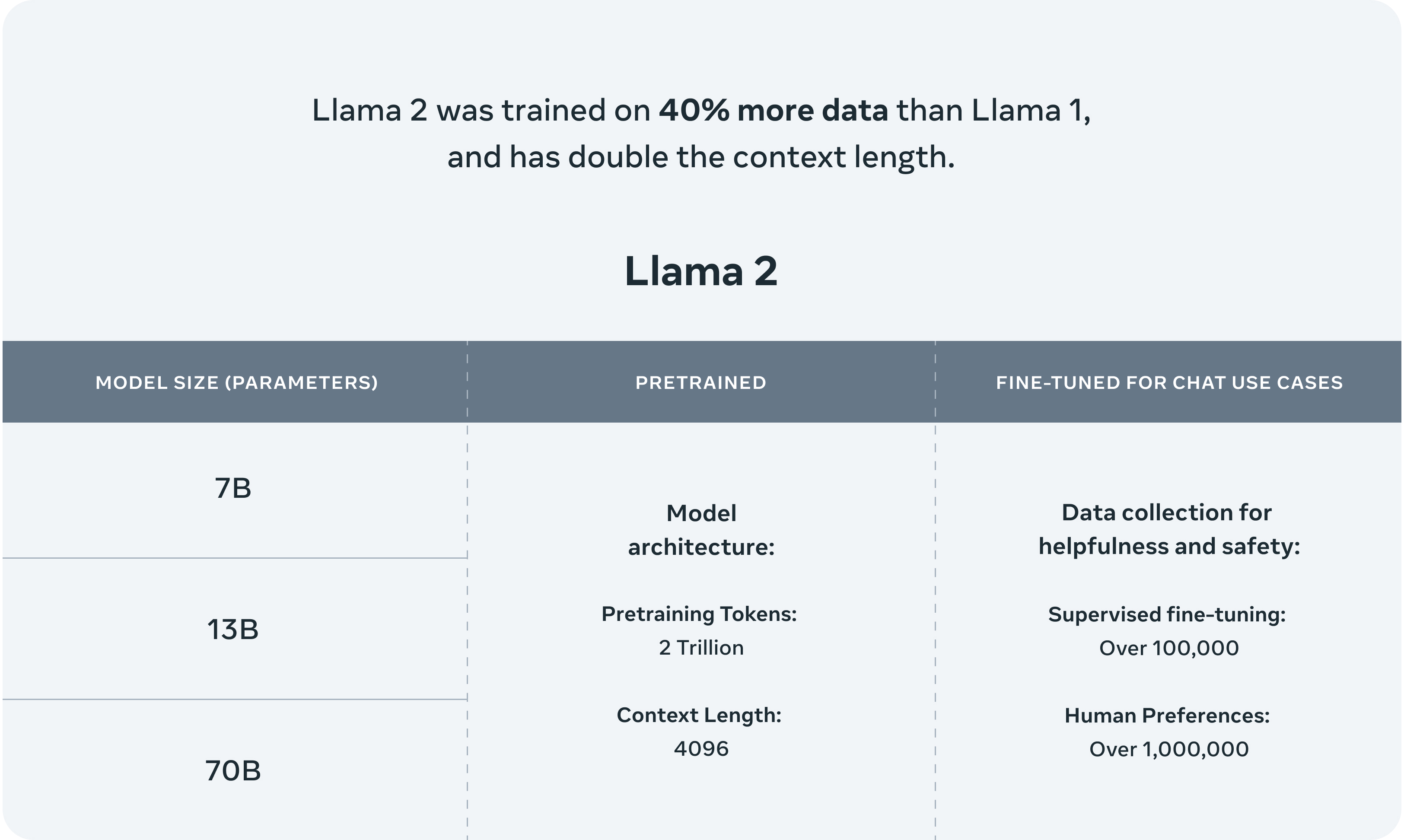
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases.
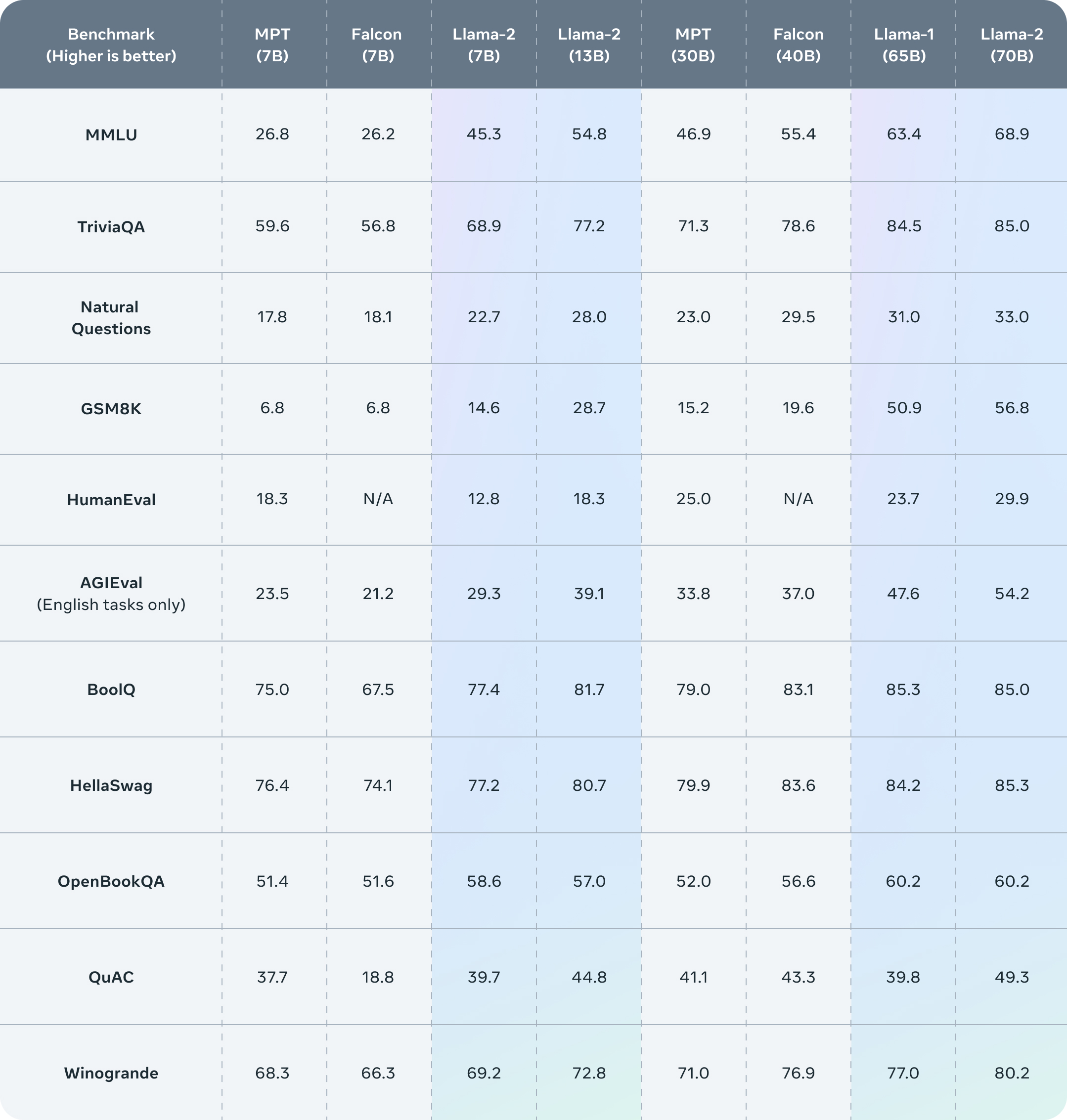
Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.
Inside the Model
With each model download you'll receive:
- Model code
- Model Weights
- README (User Guide)
- Responsible Use Guide
- License
- Acceptable Use Policy
- Model Card
Benchmarks
Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests. It was pretrained on publicly available online data sources. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations.
RLHF & Training
Llama-2-chat uses reinforcement learning from human feedback to ensure safety and helpfulness. Training Llama-2-chat: Llama 2 is pretrained using publicly available online data. An initial version of Llama-2-chat is then created through the use of supervised fine-tuning. Next, Llama-2-chat is iteratively refined using Reinforcement Learning from Human Feedback (RLHF), which includes rejection sampling and proximal policy optimization (PPO).
The License
Our model and weights are licensed for both researchers and commercial entities, upholding the principles of openness. Our mission is to empower individuals, and industry through this opportunity, while fostering an environment of discovery and ethical AI advancements.
Partnerships
We have a broad range of supporters around the world who believe in our open approach to today’s AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of Llama and an open platform as we do.
The/CUT
With the release of Llama 2, Meta has opened up new possibilities for the development and application of large language models. This free open-source AI not only accelerates access but also allows for greater innovation in the field.
Take Three:
- Video Game Analogy: Just like getting a powerful, rare (or previously banned) item drop in a game, Llama 2's release gives developers a powerful tool they can use and customize for their unique quests in the world of AI.
- Cooking Analogy: Imagine if a world-class chef decided to share their secret recipe with everyone. That's Llama 2, a secret recipe now open for all to use, adapt, and improve upon in the kitchen of AI development.
- Construction Analogy: Llama 2 is like a top-grade construction tool now available to all builders. It opens up new possibilities for constructing advanced AI structures that were previously hard to achieve.
Links
Here are the key resources discussed in this post:
Want to get started with free open-source artificial intelligence, but don't know where to begin?
Try starting here:
If you found anything else about this post interesting - consider subscribing to [email protected] where I do my best to keep you in the know about the most important updates in free open-source artificial intelligence.
This particular announcement is exciting to me because it may popularize open-source principles and practices for other enterprises and corporations to follow.
We should see some interesting models emerge out of Llama 2. I for one am looking forward to seeing where this will take us next. Get ready for another wave of innovation! This one is going to be big.

22
23
24
view more: next ›