LocalLLaMA
2580 readers
22 users here now
Community to discuss about LLaMA, the large language model created by Meta AI.
This is intended to be a replacement for r/LocalLLaMA on Reddit.
founded 2 years ago
MODERATORS
1
2
3
Yesterday I got bored and decided to try out my old GPUs with Vulkan. I had an HD 5830, GTX 460 and GTX 770 4Gb laying around so I figured "Why not".
Long story short - Vulkan didn't recognize them, hell, Linux didn't even recognize them. They didn't show up in nvtop, nvidia-smi or anything. I didn't think to check dmesg.
Honestly, I thought the 770 would work; it hasn't been in legacy status that long. It might work with an older Nvidia driver version (I'm on 550 now) but I'm not messing with that stuff just because I'm bored.
So for now the oldest GPUs I can get running are a Ryzen 5700G APU and 1080ti. Both Vega and Pascal came out in early 2017 according to Wikipedia. Those people disappointed that their RX 500 and RX 5000 don't work in Ollama should give Llama.cpp Vulkan a shot. Kobold has a Vulkan option too.
The 5700G works fine alongside Nvidia GPUs in Vulkan. The performance is what you'd expect from an APU, but at least it works. Now I'm tempted to buy a 7600 XT just to see how it does.
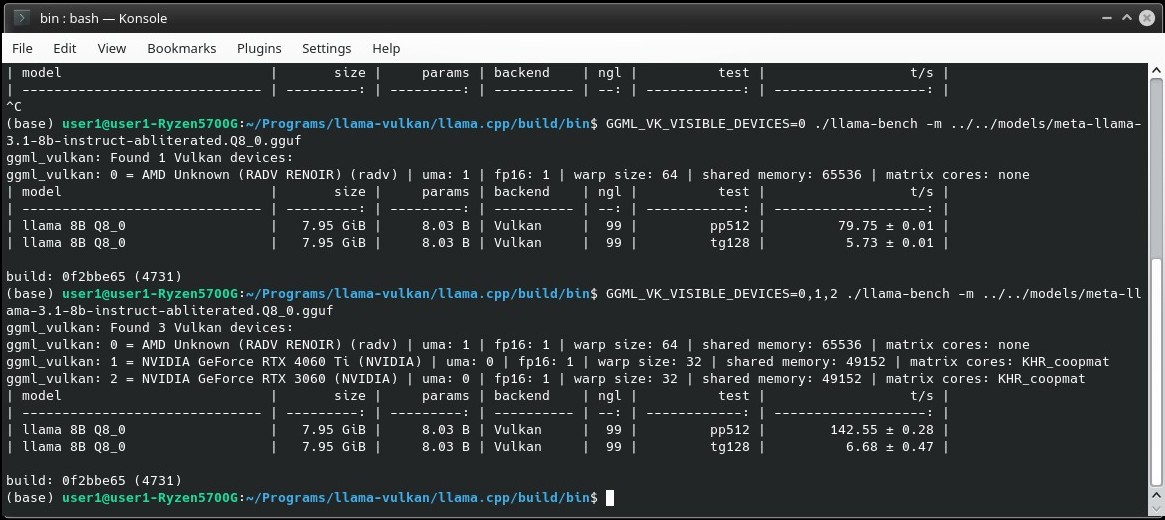
Has anyone else out there tried Vulkan?
4
Well, it was nice ... having hope, I mean. That was a good feeling.
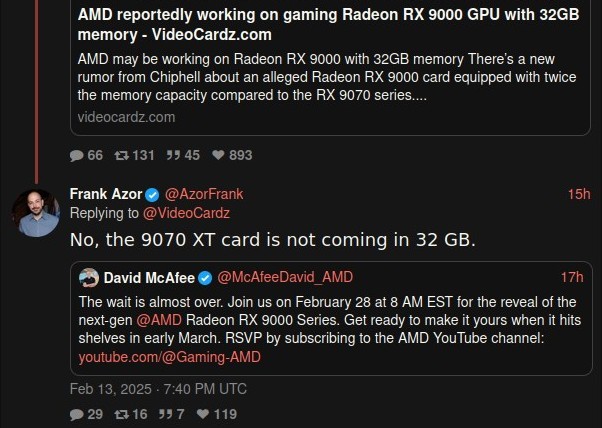
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Changed title because no need for youtube clickbait here
19
Someone asked about how llms can be so good at math operations. My response comment kind of turned into a five paragraph essay as they tend to do sometimes. Thought I would offer it here and add some reference. Maybe spark some discussion?
What do language models do?
LLMs are trained to recognize, process, and construct patterns of language data into high dimensional manifold plots.
Meaning its job is to structure and compartmentalize the patterns of language into a map where each word and its particular meaning live as pairs of points on a geometric surface. Its point is placed near closely related points in space connected by related concepts or properties of the word.
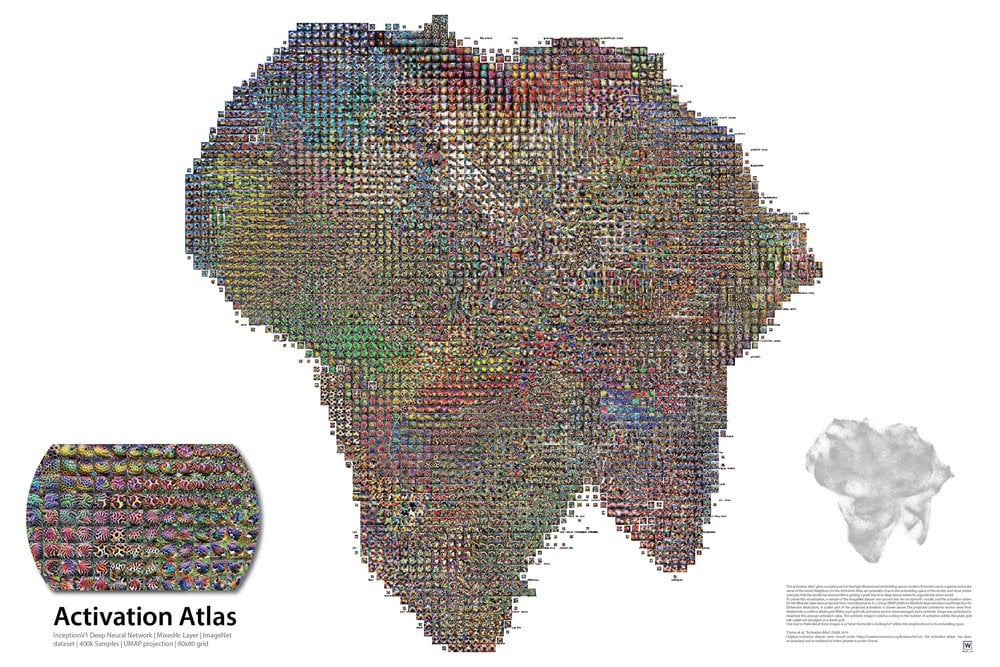
You can explore such a map for vision models here!
Then they use that map to statistically navigate through the sea of ways words can be associated into sentences to find coherent paths.
What does language really mean?
Language data isnt just words and syntax, its underlying abstract concepts, context, and how humans choose to compartmentalize or represent universal ideas given our subjective reference point.
Language data extends to everything humans can construct thoughts about including mathematics, philosophy, science storytelling, music theory, programming, ect.
Language is universal because its a fundimental way we construct and organize concepts. The first important cognative milestone for babies is the association of concepts to words and constructing sentences with them.
Even the universe speaks its own language. Physical reality and logical abstractions speak the same underlying universal patterns hidden in formalized truths and dynamical operation. Information and matter are two sides to a coin, their structure is intrinsicallty connected.
Math and conceptual vectors
Math is a symbolic representation of combinatoric logic. Logic is generally a formalized language used to represent ideas related to truth as well as how truth can be built on through axioms.
Numbers and math is cleanly structured and formalized patterns of language data. Its riggerously described and its axioms well defined. So its relatively easy to train a model to recognize and internalize patterns inherent to basic arithmetic and linear algebra and how they manipulate or process the data points representing numbers.
You can imagine the llms data manifold having a section for math and logic processing. The concept of one lives somewhere as a point of data on the manifold. By moving a point representing the concept of one along a vector dimension that represents the process of 'addition by one' to find the data point representing two.
Not a calculator though
However an llm can never be a true calculator due to the statistical nature of the tokenizer. It always has a chance of giving the wrong answer. In the infinite multitude of tokens it can pick any number of wrong numbers. We can get the statistical chance of failure down though.
Its an interesting how llms can still give accurate answers for artithmatic despite having no in built calculation function. Through training alone they are learning how to apply simple arithmetic.
hidden structures of information
There are hidden or intrinsic patterns to most structures of information. Usually you can find the fractal hyperstructures the patterns are geometrically baked into in higher dimensions once you go plotting out their phase space/ holomorphic parameter maps. We can kind of visualize these fractals with vision model activation parameter maps. Welch labs on yt has a great video about it.
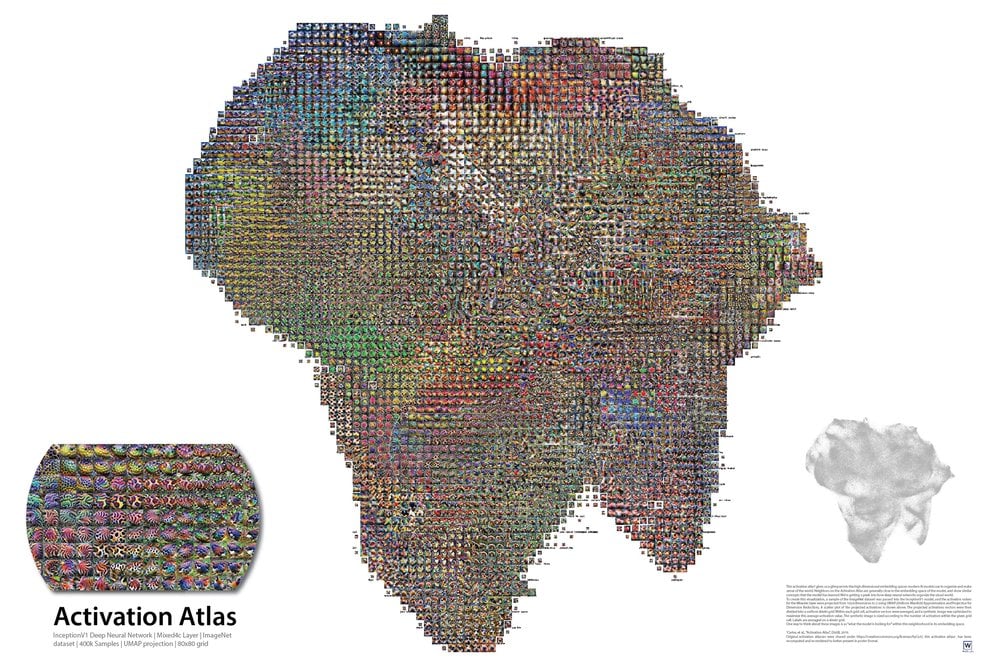
Modern language models have so many parameters with so many dimensions the manifold expands into its impossible to visualize. So they are basically mystery black boxes that somehow understand these crazy fractal structures of complex information and navigate the topological manifolds language data creates.
conclusion
This is my understanding of how llms do their thing. I hope you enjoyed reading! Secretly I just wanted to show you the cool chart :)
20
21
22
23
I am excited to see how this performs when it drops around May.

25
view more: next ›