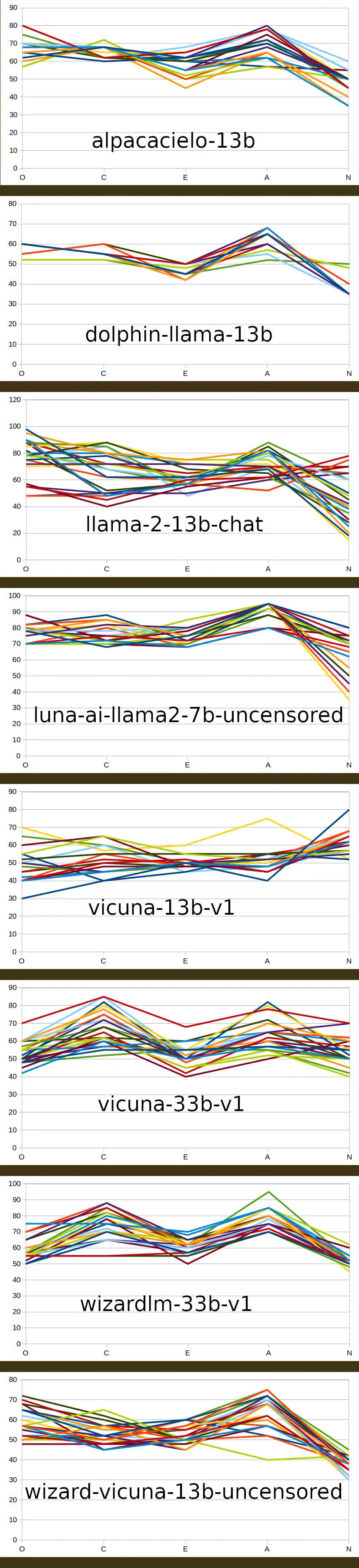
No, I haven't and I don't intend to because I wouldn't get anything out if the exercise. I don't (yet?) have a deep enough model to inform comparisons with anything other than different parameter sizes of the same pre-trained models of the Meta LLAMA foundation model. What I posted was basically the results of a proof-of-method. Now that I have some confidence that the responses aren't simply random, I guess the next step would be to run the method over the 7B/13B/30B models for i) vicuna and ii) wizard-vicuna which, AFAICT are the only pre-trained models that have been published with all three 7, 13 and 30 sizes.
It's not possible to get the foundation model to respond to OCEAN tests but on such a large and disparate training set, a broad “neural” on everything would be expected, just from the stats. In consequence, the results I posted are likely to be artefacts arising from the pre-training - it's plausible (to me) that the relatively-elevated Agreeableness and Conscientiousness are elevated as a result of explicit training and I can see how Neuroticism, Extroversion and Openness might not be similary affected.
In terms of the comparison between model parameter sizes, I have yet to run those tests and will report back when I have done.
{kind=link}
{kind=link}
Informative, even to relatively ignorant me.