1
Stable Diffusion
4217 readers
10 users here now
Discuss matters related to our favourite AI Art generation technology
Also see
Other communities
founded 1 year ago
MODERATORS
2
Text:
Emad@EMostaque
Delighted to announce the public open source release of #StableDiffusion!
Please see our release post and retweet! stability.ai/blog/stable-di...
Proud of everyone involved in releasing this tech that is the first of a series of models to activate the creative potential of humanity
11:07 AM • Aug 22, 2022
3
4
14
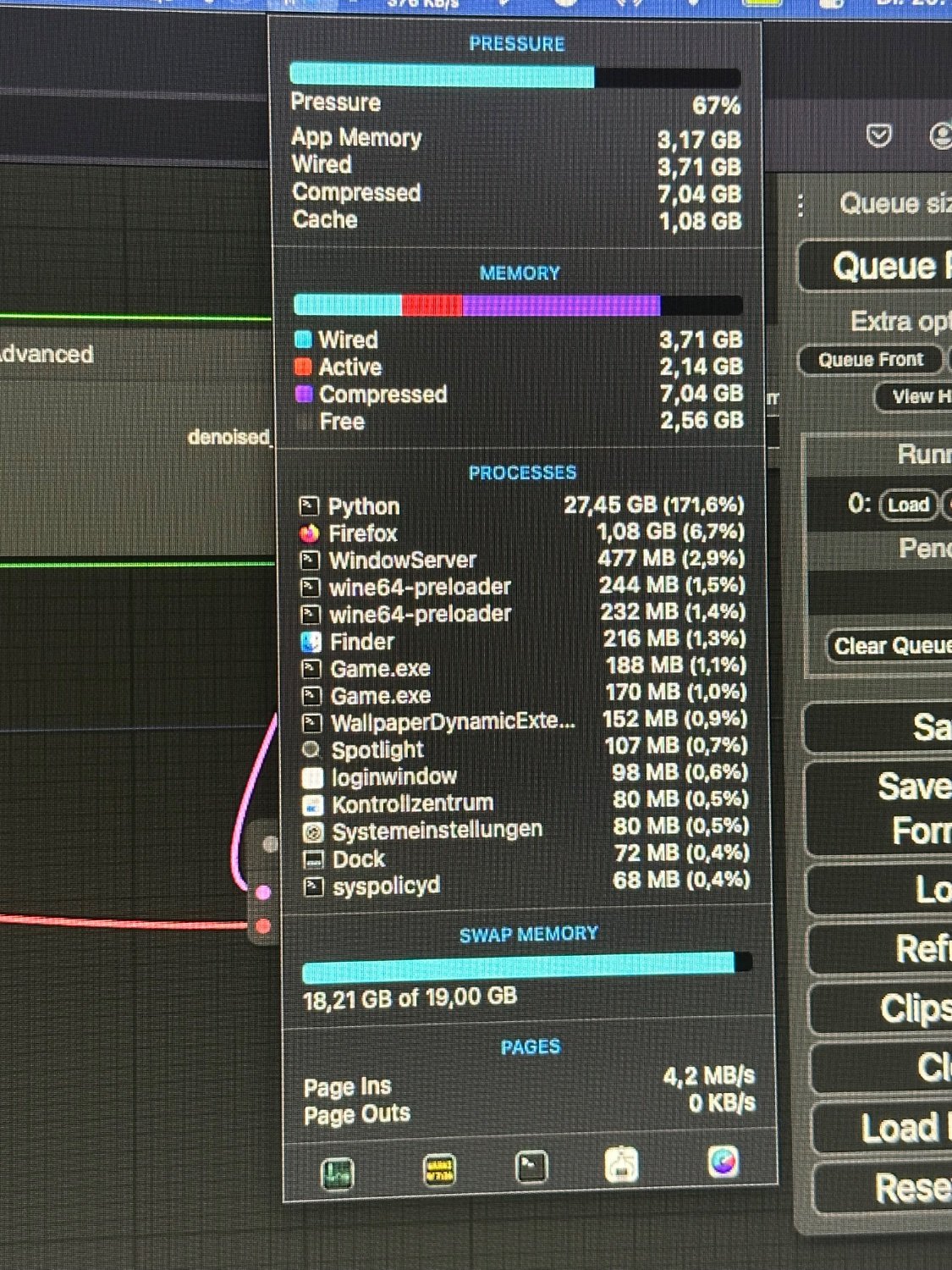
Flux via ComfyUI on M1 MacBook Air 16 GB RAM 256GB - a second later it threw an error and died
(lemmy.world)
Has anyone of you stumbled upon any information on how to get it running on machines like mine, or does it just not have enough power?
5
6
8
9

11
12
13
14
15
16
54
Linux Foundation Welcomes the Open Model Initiative to Promote Openly Licensed AI Models
(www.linuxfoundation.org)
17
18
19
20
21
22
23
24
From The Hugging Face Model Card:
Not Ready
This is a WIP and not ready for use. This is an early testing version for research and development. You may know what this is and how to use it, if so, feel free, but it will change as I continue to develop it. I plan to do many updates to it frequently. So you may want to set a revision if you intend to use it anyway.
What is this?
FLUX.1-schnell is an amazing distilled model with an apache 2.0 license. However, it is not finetunable. LoRAs, IP adapters, control nets, etc, cannot be trained on it because it is distilled. The goal of this project is to finetune a non-distilled version of it that can be used as a training base to train adapters for FLUX.1-schnell.
Current Issues
Since we are breaking the distillation, this model will need many steps and guidance to produce good results. Currently, this model, like the schnell version, does not have guidance embeddings. Because of this (and possible other factors) images generated with this model will not look great. However, this hopefully will not affect training, since guidance is not used during training. The things trained on this model are intended to be used on the schnell version anyway. I am working on training guidance embeddings for it, but hopefully it will work as a training base without them.



{kind=link}
view more: next ›