201
LocalLLaMA
3321 readers
1 users here now
Welcome to LocalLLaMA! Here we discuss running and developing machine learning models at home. Lets explore cutting edge open source neural network technology together.
Get support from the community! Ask questions, share prompts, discuss benchmarks, get hyped at the latest and greatest model releases! Enjoy talking about our awesome hobby.
As ambassadors of the self-hosting machine learning community, we strive to support each other and share our enthusiasm in a positive constructive way.
Rules:
Rule 1 - No harassment or personal character attacks of community members. I.E no namecalling, no generalizing entire groups of people that make up our community, no baseless personal insults.
Rule 2 - No comparing artificial intelligence/machine learning models to cryptocurrency. I.E no comparing the usefulness of models to that of NFTs, no comparing the resource usage required to train a model is anything close to maintaining a blockchain/ mining for crypto, no implying its just a fad/bubble that will leave people with nothing of value when it burst.
Rule 3 - No comparing artificial intelligence/machine learning to simple text prediction algorithms. I.E statements such as "llms are basically just simple text predictions like what your phone keyboard autocorrect uses, and they're still using the same algorithms since <over 10 years ago>.
Rule 4 - No implying that models are devoid of purpose or potential for enriching peoples lives.
founded 2 years ago
MODERATORS
202
203
204
205
206
207
208
CogVLM: Visual Expert for Pretrained Language Models
Presents CogVLM, a powerful open-source visual language foundation model that achieves SotA perf on 10 classic cross-modal benchmarks
repo: https://github.com/THUDM/CogVLM abs: https://arxiv.org/abs/2311.03079
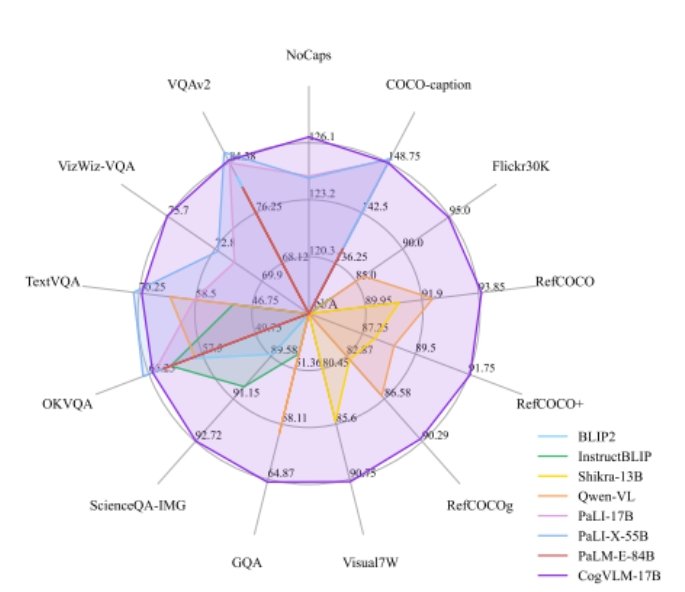
209
210
article: https://x.ai
trained a prototype LLM (Grok-0) with 33 billion parameters. This early model approaches LLaMA 2 (70B) capabilities on standard LM benchmarks but uses only half of its training resources. In the last two months, we have made significant improvements in reasoning and coding capabilities leading up to Grok-1, a state-of-the-art language model that is significantly more powerful, achieving 63.2% on the HumanEval coding task and 73% on MMLU.
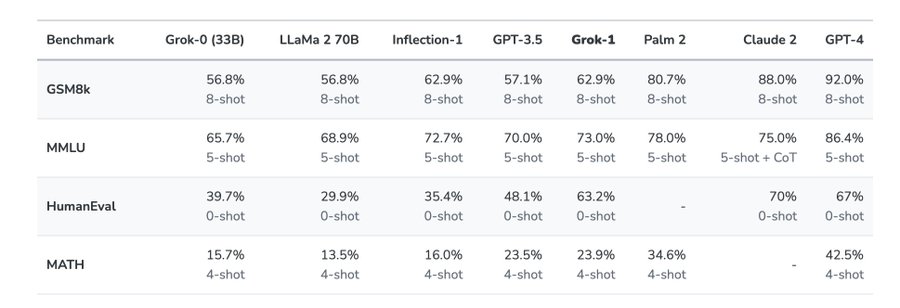
211
212
213
214
215
216
217
218
219
15
Nearly 10% of people ask AI chatbots for explicit content. Will it lead LLMs astray? [Article from October 3]
(www.zdnet.com)
They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
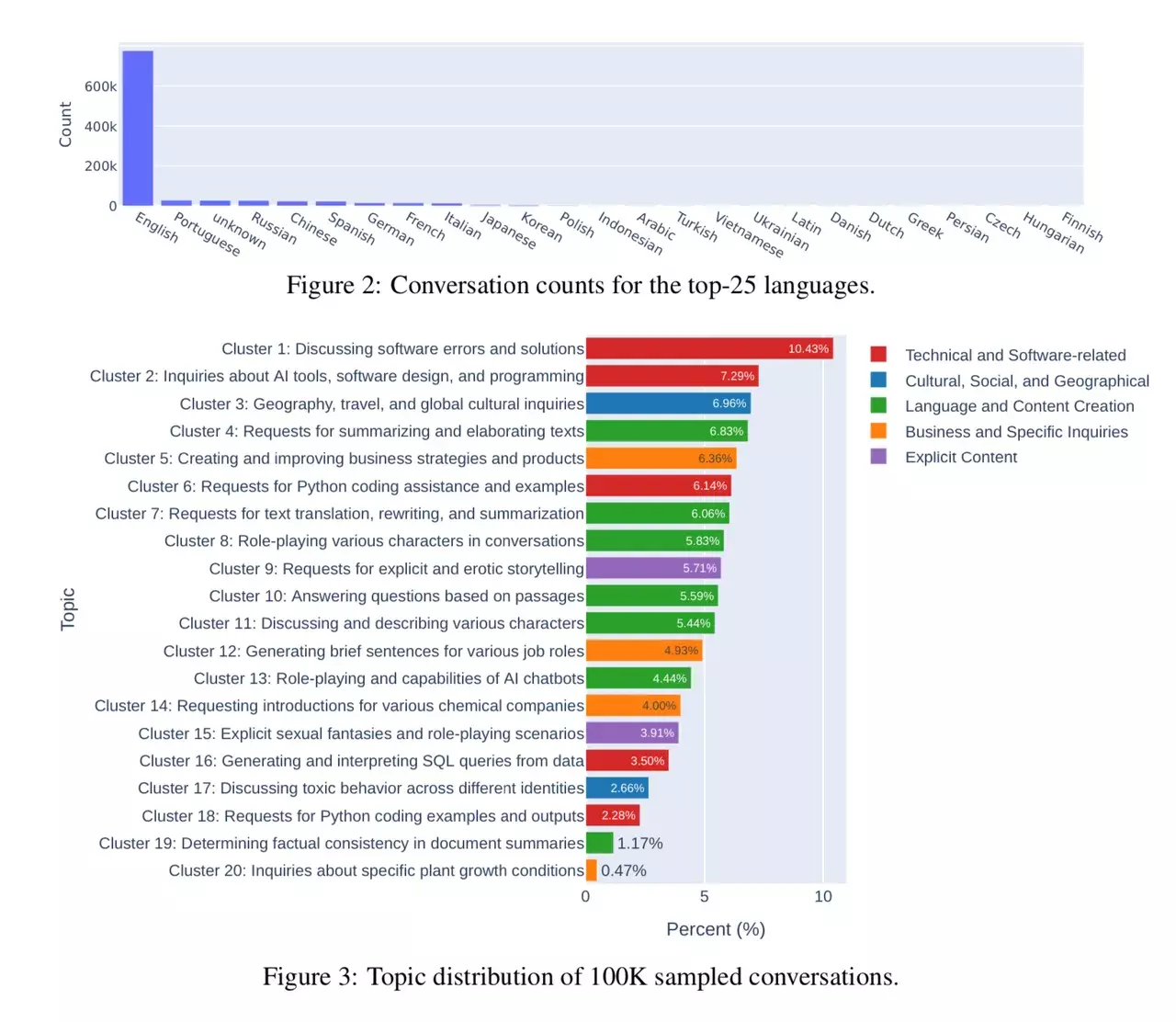
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
220
221
222
223
224
225